


ACTUALITÉ
| Démystifier les LLMs : Enjeux et opportunités de l’IA générative
Les progrès fulgurants de l’intelligence artificielle (IA), notamment dans le domaine du traitement du langage naturel (NLP), ont permis de développer de nouveaux types d’algorithmes qui peuvent créer automatiquement du contenu. Qu’il s’agisse de texte, d’images, d’audio ou de vidéo, l’intelligence artificielle dite générative a connu en 2023 une progression remarquable et un intérêt croissant, à l’instar du désormais incontournable ChatGPT[1] et exemple emblématique de cette révolution technologique.
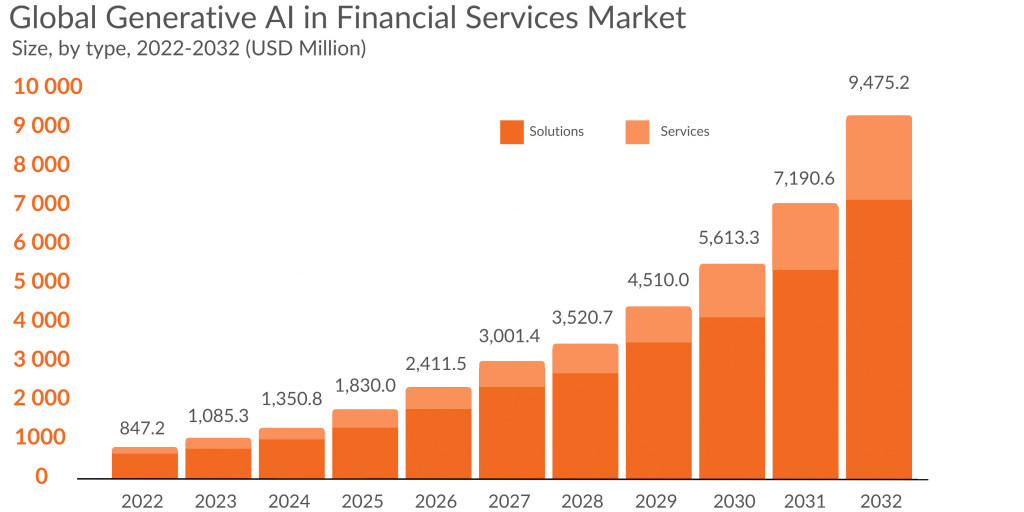
Bien que nous soyons qu’aux prémices, les perspectives d’applications potentielles de l’IA générative dans le secteur financier sont extrêmement prometteuses. En chiffre, le marché[2] des services financiers devrait connaître une croissance fulgurante, passant de 847,2 millions de dollars en 2022 à 9475,2 millions de dollars d’ici 2032 soit une progression à un taux annuel moyen de 28%. L’IA générative est donc bien une véritable technologie de rupture qui bouleverse tous les secteurs, en particulier celui des finances.
Services financiers : de l'IA à l'IA générative
En offrant une vision holistique de l’entreprise et en automatisant de nombreuses tâches chronophages, l’intelligence artificielle générative promet de révolutionner la fonction finance. Cette technologie facilitera la prise de décisions en connectant les données opérationnelles, commerciales et financières pour produire des analyses approfondies. L’IA optimisera les processus de facturation, de paiement, de recouvrement et de gestion de trésorerie au cœur de la production d’informations financières. En traitant les rapprochements, les consolidations et la documentation comptable, elle automatisera la production des comptes. De plus, elle fournira un résumé des contrats complexes et des recommandations pour leur traitement conformément aux normes IFRS. Cette technologie, quelle que soit la juridiction concernée, calculera les impôts, générera les déclarations et analysera l’impact des nouvelles réglementations dans le domaine fiscal. Grâce à cette technologie, l’IA générative deviendra un détecteur de signaux faibles en utilisant ses capacités d’analyse pour détecter les transactions suspectes, les manquements aux procédures internes et proposer des mécanismes de réponses appropriées. générative.
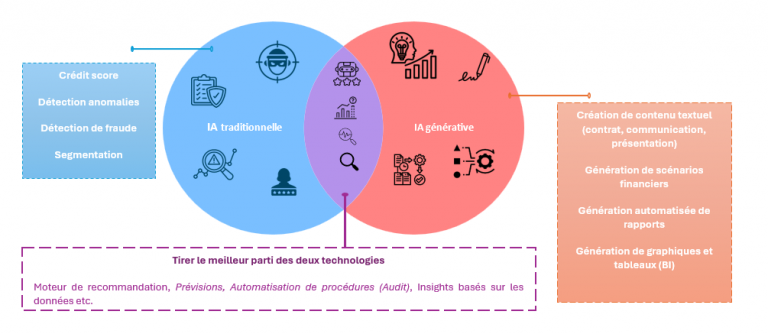
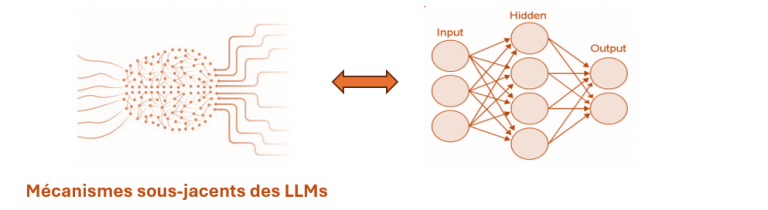
Apprentissage automatique et Deep Learning : Les fondations des LLMs
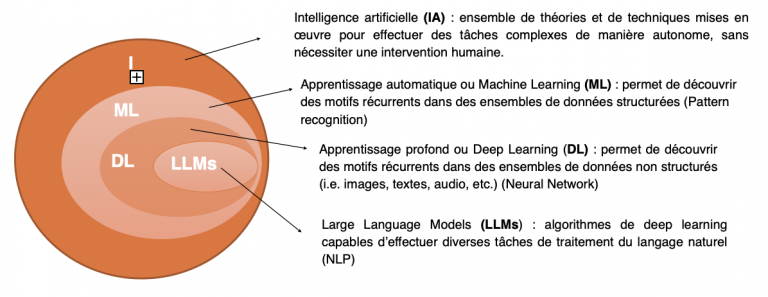
Apprentissage automatique
Deep Learning
OUTPUT
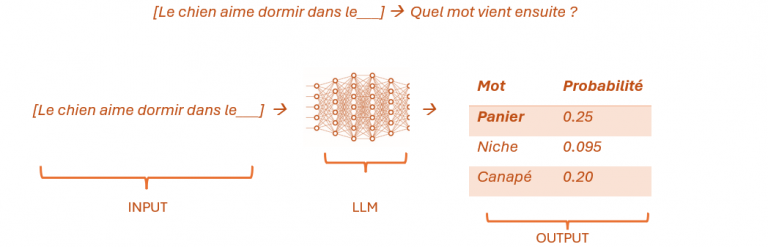
Modélisation du language

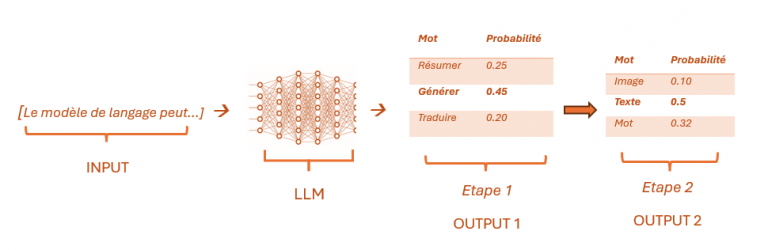
L’image ci-dessus montre comment cela se fait. Une seule séquence peut être transformée en plusieurs séquences pour l’entraînement. Chaque séquence de mots est divisée en plusieurs sous-séquences, chacune étant utilisée comme entrée pour le LLM, avec le mot suivant comme étiquette (auto-supervisée [5]). Grâce à une quantité massive de données d’entraînement et à un réseau de neurones suffisamment grand, le LLM devient très performant pour prédire le prochain mot approprié [6] d’un point de vue syntaxique et sémantique dans n’importe quel contexte. En généralisant, nous obtenons l’image ci-dessous.
-
Après avoir illustré l’idée des LLMs, on pourrait se poser la question sur la relation avec la famille des modèles Generative Pre-trained Transformer (GPT). Dès lors, une précision est importante : le LLM n’est que la première étape dans le développement !
En effet, dans l’acronyme GPT, si le « G » indique que le modèle est entraîné de manière générative à produire du texte et que le « T » fait référence à l’architecture Transformer qui permet une attention sélective sur les parties les plus pertinentes des données d’entrée, c’est le « P » pour « Pre-trained » qui est crucial. Les grands modèles de dialogue comme ChatGPT ne sont pas simplement entraînés en une seule fois. Ils suivent un pipeline d’entraînement en plusieurs phases. La modélisation de langage n’est donc que le point de départ d’un système beaucoup plus complexe.
Phases d'entrainement des LLMs
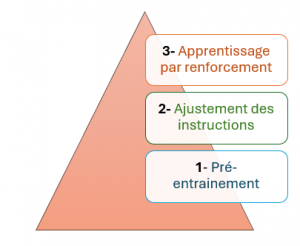
Pré-entrainement : C’est l’étape que nous venons de décrire, où le modèle acquiert une maîtrise de la grammaire, de la syntaxe et des connaissances générales.
L’ajustement des instructions qui permet d’aligner le LLM sur les intentions humaines afin qu’il réponde de manière appropriée aux questions et instructions
Apprentissage par renforcement à partir de commentaires humains : Pour certains LLMs, un apprentissage par renforcement à partir de commentaires humains contribue davantage à cet alignement sur les valeurs et préférences.
[5]Nous n’avons même pas besoin d’étiqueter les données, car le mot suivant lui-même est l’étiquette, c’est pourquoi on l’appelle aussi l’apprentissage auto-supervisé.
[6] Échantillonner parmi les mots les plus probables au lieu du plus probable permet plus de créativité. Certains LLMs ajustent le niveau de créativité/déterminisme.
Limites des LLMs et stratégies d'atténuation
Conclusion
L’IA générative représente une opportunité unique pour les institutions financières de repenser leurs services et d’optimiser leurs processus. Cependant, son adoption nécessite une compréhension approfondie de ses mécanismes, de ses capacités émergentes ainsi que des stratégies d’atténuation des risques associés. Comme pour toutes les technologies émergentes, il existe des défis à relever, notamment en matière de qualité des données. Il est essentiel que les entreprises utilisent des données de formation de haute qualité pour éviter les biais dans les résultats. En naviguant habilement dans ce paysage en constante évolution, les acteurs financiers peuvent se positionner à l’avant-garde et offrir des services véritablement différenciés, tout en maintenant des niveaux élevés de fiabilité, de transparence et d’éthique.

Les banques à l’avant-garde de l’IA générative
► Swift : Ouverte aux innovations, Swift salue l’impact transformateur de ChatGPT et GPT-4 selon son responsable IA Chalapathy Neti.
► ABN Amro : Teste l’IA générative pour automatiser la synthèse des interactions clients et améliorer la collecte de données.
► ING Bank : Expérimente l’IA générative pour la refactorisation de code et l’analyse comportementale des clients.
► Goldman Sachs : Projets pilotes d’automatisation de la génération et des tests de code. Héberge la startup « Louisa » dans son incubateur.
► Morgan Stanley : Déploie un chatbot OpenAI pour améliorer le support aux conseillers financiers avec une recherche et création de contenu personnalisés..
Source : marketsandmarkets.com.
